
How Data Science Identifies and Eliminates Spam Networks

If you are active on Twitter you will have experienced being followed by spam accounts. These vast networks of spammers also appear when undertaking social data analysis (as we do as a core part of our business). In the search for who is influencing whom, for the key topics of conversation, and for who is connected to whom, the large spam networks pollute and distort the results. Applying data science allows us to eliminate their influence.
Spammers pollute social data insights
Focusing on Twitter, spam networks pollute social data analytics insights because of a number of factors.:
Through sheer network size they change the network analysis;
They pollute the textual analyses; and,
They distort statistics and timelines.
Firstly they are large networks because the very nature of what they are doing requires that they build as large a network as possible in the shortest time. The spammers are being identified and shut down by Twitter as quickly as Twitter can manage, so the spammers have to continually spawn new fake accounts and cross-link them very rapidly. They’ll aim to grow a few hyper nodes with say 200,000 followers in a few days, and then a ring of super nodes with 100,000+ members and then thousands of worker nodes which try to get to say 2,000 members before being squashed by Twitter, at which time they regenerate (see the image on right above of new accounts).
The sheer size of these networks means that in a typical social media analysis, almost regardless of the particular maths each vendor uses, the hyper and super nodes will be ranked highly as “authoritative” and “influential”. Furthermore this will occur for any active topic because as soon as a topic becomes active the spam networks latch on to it. That’s the first point of degradation of insights because without data science the spammers have to be eliminated “by sight” as it were.
Secondly, because of their “influence” and “authority” the content within the spammer networks will pollute all of the “textual” analysis which you rely upon to gather insights e.g. the wordclouds, the buzzgraphs, and the overall sentiment analysis. Thirdly the spam networks will also distort the basic activity statistics, and the demographics and the popularity time lines.
So all-in-all the large networks of spammers attaching to topics makes life difficult for people like ourselves and others seeking to find the real topics, the real influencers and the real activity statistics. The danger, if you choose a person as a potential influencer for marketing purposes who is strongly linked to spammer networks, is that these spammer networks will immediately gravitate to surround your clients and topics, and that just creates more zero-value work to clean up.
Luckily, data science provides us with an elegant and effective answer.
Spammers of a feather cluster together

The answer lies in the way spammers have to rapidly cross-link to build their networks. This cross-linking means they build clusters around their hypernodes and supernodes and these clusters have a distinct mathematical signature. Check out the amazing image at right – this is maths honing in on a supernode cluster of spammers – fantastic!
To get this clustering the maths reaches out through the people associated with a search topic and keeps connecting as many as it can – this is a kind of algorithmic race. Ultimately, via the “6 degrees of separation” everyone is connected to everyone, which means if left unchecked we would be back where we started without the data science and having everyone as one giant cluster around the topic. So at a certain point the algorithms have an “aha” moment when they realise that they have just connected Donald Trump with Hillary Clinton. At this point they stop racing, reverse gears, and go into a long hill-climbing Terminator mode to break connections between people who don’t look like each other with respect to the topic.
At every step back programmatic judgement has to be applied to determine if the people being disconnected are looking more like the people that they remain connected to than the people with whom they have been disconnected. Japanese culture, language and business is driven by the concept of In-Group and Out-Group (unlike Chinese business and culture being driven by “quanxi” and family). The algorithms continually review which “In-Group” people should belong to, and how many groups there should be.
This is when the response to your enquiry gets slow as the numbers as crunched and reviewed against some target of “optimality” – clusters need to be not too compact to create thousands of them and not too large to become ineffective in facilitating insights. The algorithms have a bunch of levers which are pulled to achieve this optimality. The answer comes out to be what you see below.
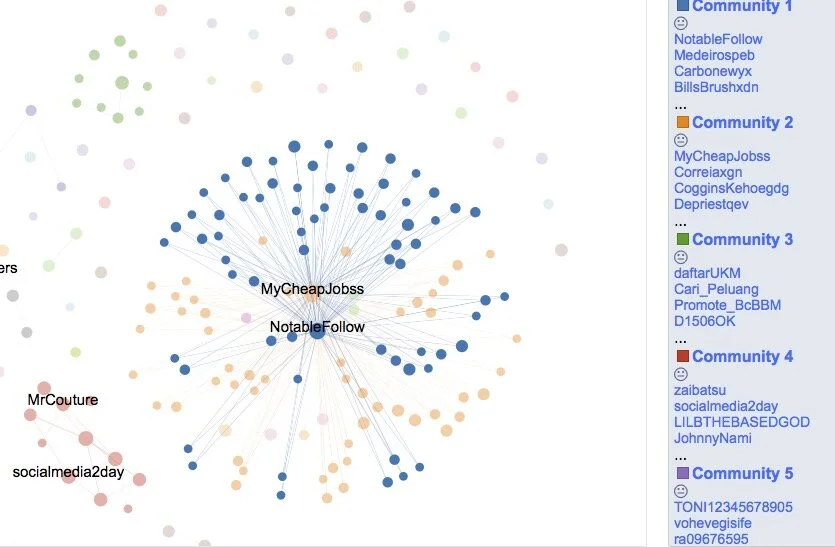
The image (above) shows an optimal grouping according to the selected parameters and it is very distinct how this spam network revolves around the supernode of @mycheapjobss. If we dig to another level of detail, we can see how this supernode jumped in followers by about 100,000 over 2 days, this is the “network build” stage when the spammers go on the attack. Although this is a typical signature of spammers Twitter does not seem to have alerts which notify them to check and shut them down, or perhaps they have a large backlog and they are simply unable to keep up. This spam community has been multiplying for about 3 weeks.

How do we use this knowledge to eliminate spam networks?
The good news is that when such spam networks attach themselves to a topic, especially one which is trending, the data science allows us to cluster the spammers together more closely than with the non-spam participants. Simply, this means that visually the spam networks will hang off the edge of the other networks, and that by investigating the associated data analytics and twitter profiles that you will be able to identify the “participants of interest” (check the links below).
If you are using a tool like Sysomos MAP then you will also be able to examine conversations within those communities of interest – in relation to the topic – and the associated analysis of influencers, authority, reach, wordclouds and buzzgraphs will untainted by the spam networks.